Opus 4.8: What Launched & Reddit Reviews
Co-founder at King’s Cross Labs · ex-LinkedIn PM & Forbes 30 Under 30
Every time a new AI model launches, the headline is always the same: best model ever, crushing the benchmarks. Then you open it, ask it to rewrite an email, and wonder if you're doing something wrong.
That's where I went with Opus 4.8. I skipped the press release and went straight to Reddit, which might be the most honest review system on the planet. People there aren't trying to sell you anything. They're just annoyed, impressed, or both. Here's what actually matters if you're a non-coder trying to decide whether this upgrade is worth your attention.
What launched
On May 28, 2026, Anthropic released Claude Opus 4.8, an upgrade to Opus 4.7. Same price. Better benchmarks across the board. Anthropic's framing: a more effective collaborator, not just a smarter answer machine.

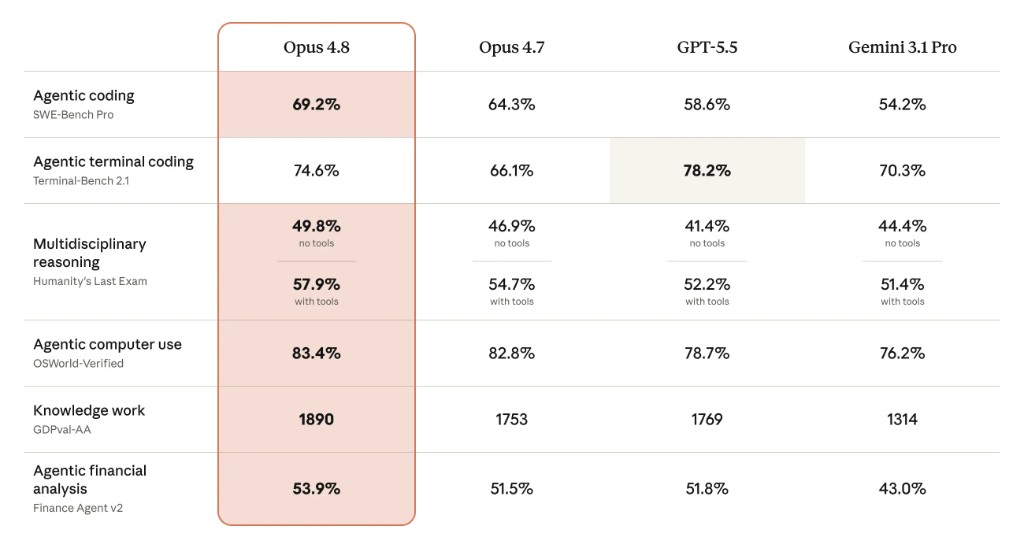
The benchmark slide looks strong. Opus 4.8 leads in most categories against Opus 4.7, GPT-5.5, and Gemini 3.1 Pro: agentic coding, reasoning, computer use, knowledge work, and financial analysis. The one exception is terminal coding, where GPT-5.5 still edges it out.
But the model wasn't the only thing that launched. Three features shipped alongside it:
1. Effort controls on claude.ai You can now tell Claude how hard to work on a task: Low, Medium, High, or Max. This is the feature Reddit says matters more than the model number itself. More on that below.
2. Dynamic workflows in Claude Code A feature for tackling very large, multi-step problems. Mostly relevant if you're using Claude's coding tools, but it signals where Anthropic is headed: less "answer my question," more "go do this whole project."
3. Fast mode got cheaper Opus 4.8 can run at 2.5× speed in fast mode, and that mode is now three times cheaper than it was for previous Opus models.
Positives
1. It's upfront about its shortcomings
Opus 4.8 catches its own mistakes more often. Anthropic said it's "4× less likely to let flaws pass unremarked," and that shows up in everyday use.
When something in your prompt is weak, it says so. When it's not sure about a fact, it flags the uncertainty instead of bluffing. Fewer confident-but-wrong answers. If you use Claude for research, planning, or anything where being wrong is expensive, that's a real upgrade over a model that just sounds right.
2. Effort controls change everything
This is the feature almost nobody talked about in the launch threads, and it's the one Reddit says you should test before judging the model.
Low, Medium, High, and Max effort levels noticeably change output quality. Low gives you a quick, good-enough answer. Max gives you something much more thorough. If you've only tried Opus 4.8 on the default setting, you haven't really tried Opus 4.8.
There's also an "ultracode" effort level in the Claude Code CLI that sits above Max. Early testers say the difference in thoroughness is measurable.
Key insight: The model number matters less than the effort level you pair it with. Try Max on a task you care about before deciding if 4.8 is an upgrade or a downgrade.
3. Better at technical and knowledge work
On paper and in early user reports, 4.8 is a clear step up from 4.7 for coding, analysis, and multi-step reasoning. If your Claude use skews toward spreadsheets, research, contracts, or building things, the improvements are real even if they don't show up in a casual chat.
Negatives
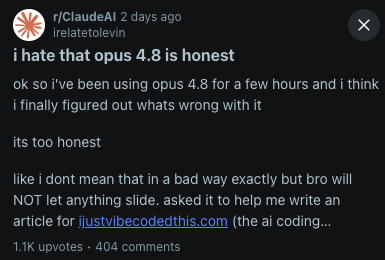
1. Sometimes too honest, painfully so
Reddit users felt this immediately. One post with 1,100+ upvotes was titled "i hate that opus 4.8 is honest." The gripe wasn't accuracy. It was that the model will not let anything slide. Ask it to gloss over a weak argument and it names the weakness. Ask it to help with something borderline and it pushes back hard.
For quick tasks where you just want a clean answer without a lecture, that level of scrutiny can feel like friction, not help.
2. It talks too much
Many Reddit users describe 4.8 as verbose, preachy, and prone to hedging. It adds disclaimers where none are needed. It explains why it's explaining things. It expresses uncertainty even when the answer is straightforward.
If you liked Claude because it gave you a clean, direct answer and moved on, 4.8 may feel like a lecturer who won't stop qualifying their points.
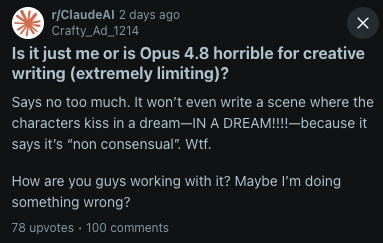
3. Creative writing took a hit
This came up repeatedly. One post asked: "Is it just me or is Opus 4.8 horrible for creative writing?" Users report the model saying no too often, over-analyzing prompts, and refusing fictional scenarios it would have handled fine in earlier versions.
If you use Claude for fiction, scripts, brainstorming wild ideas, or anything where you want the model to play along, 4.8 may frustrate you. The same caution that makes it better at analysis makes it worse at imagination.
4. Multi-step instructions are still inconsistent
Even fans of 4.8 admit it sometimes skips steps you explicitly asked for, guesses instead of checking, and finds the right answer through a messy path. You get the output you wanted, but not the process you asked for.
That matters if you're building workflows where Claude needs to follow a specific sequence: review this, then draft that, then check the third thing. It can still land correctly while cutting corners you cared about.
Comparison to previous models
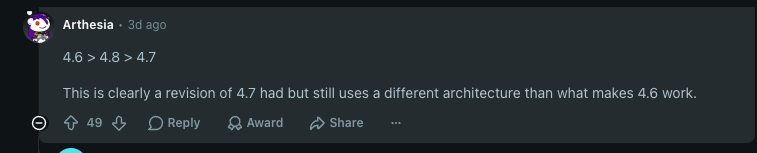
The Reddit consensus, summed up in one comment with 49 upvotes:
4.6 > 4.8 > 4.7
That's the split in a nutshell. Opus 4.8 is clearly better than 4.7. But a lot of people still prefer 4.6 for day-to-day use because it was more direct, less verbose, and less restrictive on creative tasks.
One commenter noted that 4.8 looks like a revision of 4.7's architecture, not a return to what made 4.6 feel good. So the improvements are real, but they're improvements in a specific direction: more careful, more thorough, more cautious. Not necessarily more pleasant to talk to.
Should you use it?
Yes, if: you use Claude for research, analysis, planning, coding, or any task where accuracy beats speed and you want fewer hallucinations. Pair it with the right effort level (try High or Max on important tasks) and it's a meaningful upgrade over 4.7.
Maybe not yet, if: you use Claude mainly for creative writing, casual brainstorming, or quick back-and-forth where you want short, direct answers. In those cases, 4.6 may still feel better, and switching to 4.8 could feel like a downgrade even though the benchmarks say otherwise.
Before you decide: play with effort controls. Low, Medium, High, Max. Run the same prompt at two different levels and compare. Reddit's strongest takeaway wasn't "4.8 is amazing" or "4.8 is terrible." It was: the effort setting changes the experience more than the version number.
If you haven't touched effort controls yet, do that before you judge the model.
Additional Reading
Here are some related guides to check out:
Frequently asked questions
- Is Claude Opus 4.8 worth switching to?
- It depends on what you use Claude for. Yes if you lean on it for research, analysis, planning, or coding, where it's more accurate and about 4x less likely to let flaws pass unremarked. Maybe not if you mostly do creative writing or quick casual chats, where Reddit users find it verbose, cautious, and prone to saying no. The Reddit consensus ranked it 4.6 > 4.8 > 4.7: better than 4.7, but more careful and less fun to talk to.
- Why does Opus 4.8 feel so verbose or preachy?
- That came up a lot on Reddit. 4.8 is more careful by design, so it adds disclaimers, hedges even on straightforward answers, and explains its own reasoning. The same caution that makes it better at analysis makes it wordier and more restrictive on creative tasks. If you liked Claude for clean, direct answers, pairing it with a lower effort level helps.
- What are effort controls in Claude and why do they matter?
- Effort controls let you tell Claude how hard to work on a task (Low, Medium, High, or Max), and Reddit's biggest takeaway was that this changes your experience more than the model version does. Low gives a quick, good-enough answer; Max gives you something much more thorough. If you've only used 4.8 on the default setting, try Max on a task you care about before judging the model.